IE11でテストを行ってるとき、ファイルをダウンロードしようとすると
○○○から=UTF-8_B_NV_jg5XjgqHjgqTjg6vml6XmnKzoqp4ueGxzbQ===を保存しますか?

と表示される。
もちろん名前をつけて保存をしても
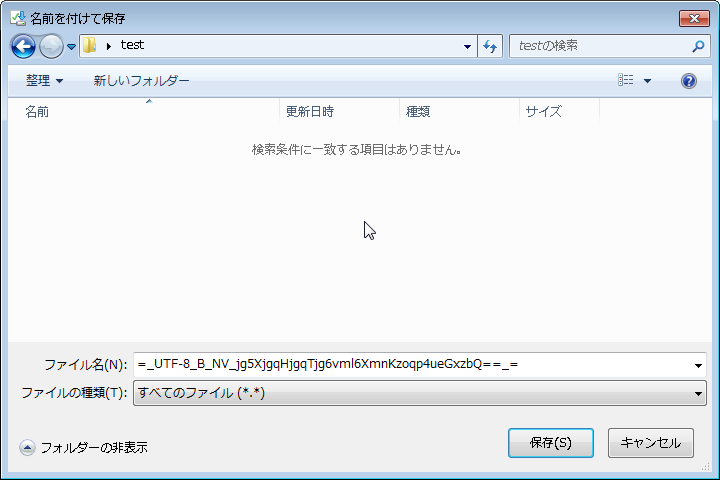
となり、拡張子もないのでなんのファイルかさえもわからない状態になります……
(ファイル自体が壊れてるわけではないので、拡張子つけて開くと正常に見れます。)
なんでUTF-8…になるのだろう?と原因を調査してみることにしました。
今回ダウンロード処理を行うには以下のプログラムにて判断をしております。
String ua = request.getHeader("User-Agent");
if (ua != null && ua.contains("MSIE")) {
filename = URLEncoder.encode(filename, "UTF-8");
}else {
filename = MimeUtility.encodeWord(fileName, "UTF-8", "B");
}ユーザーエージェントにMSIEがあれば、URLEncoder.encode関数を、それ以外はMimeUtility.encodeWord関数を使用するようにしていました。
IE10まではユーザーエージェントにMSIEが入っておりましたが、IE11はMSIEが入っていないようです。
- IE8 :Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)
- IE9 :Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0; Trident/5.0)
- IE10:Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0)
- IE11:Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko
- IE11(互換表示設定):Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; Trident/7.0;)
解決方法として
ua.contains("MSIE")のとこを
(ua.contains("MSIE")||ua.contains("Trident"))
と変更すれば大丈夫だと思います。
javascript等MSIEで判断しているとこが多いので修正規模が大きいような気がします。
互換表示設定を行えばMSIEが取れるのでそれで回避もできます。
(閲覧の履歴にて履歴を削除すると再度設定しないといけませんが……)
MSIEをTridentに置き換えればいいじゃん!と思ったのですが、IE7や一部IE8にはTridentがないみたいなので、しばらくは共存が必要ですね。
(むしろIEの独特性がなくなれば……)
{kind=link}