JavaのバージョンによりHashMapのIndexを求める方法が異なっていたのでメモ
各バージョンによる処理の違い
各バージョンのHashMapはどのように処理をしているのかソースにて見比べることにしました。
put、hashメソッド部分のみを抽出。
J2SE 1.4
インデックス番号の割り出し方法は
キー値からハッシュ値出力⇒ハッシュ値をビット演算⇒テーブルサイズでマスク
の順に行っています。
public Object put(Object key, Object value) {
Object k = maskNull(key);
int hash = hash(k);
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
if (e.hash == hash && eq(k, e.key)) {
Object oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, k, value, i);
return null;
}
static int hash(Object x) {
int h = x.hashCode();
h += ~(h << 9);
h ^= (h >>> 14);
h += (h << 4);
h ^= (h >>> 10);
return h;
}
static int indexFor(int h, int length) {
return h & (length-1);
}J2SE 1.5
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
static int hash(int h) {
return useNewHash ? newHash(h) : oldHash(h);
}
private static int newHash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
private static int oldHash(int h) {
h += ~(h << 9);
h ^= (h >>> 14);
h += (h << 4);
h ^= (h >>> 10);
return h;
}
static int indexFor(int h, int length) {
return h & (length-1);
}
/**
* Whether to prefer the old supplemental hash function, for
* compatibility with broken applications that rely on the
* internal hashing order.
*
* Set to true only by hotspot when invoked via
* -XX:+UseNewHashFunction or -XX:+AggressiveOpts
*/
private static final boolean useNewHash;
static { useNewHash = false; }
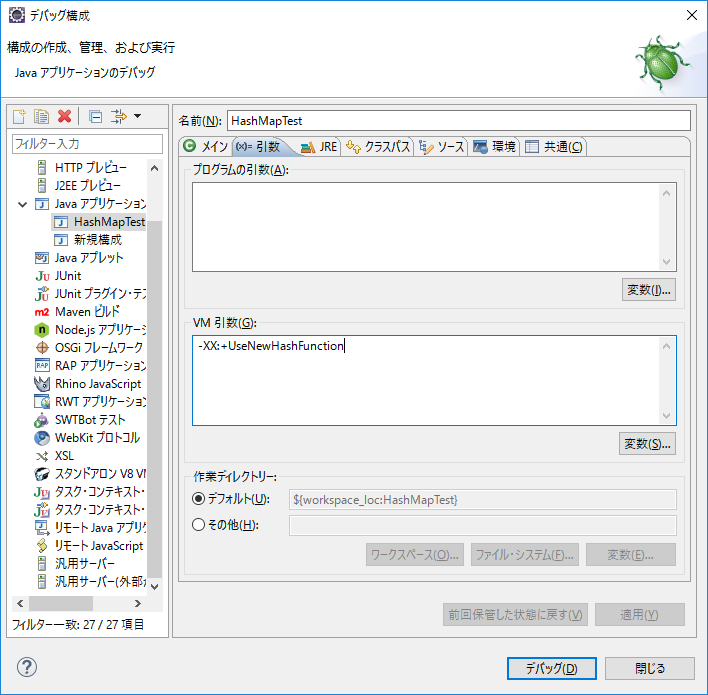
Eclipseの場合、VM引数オプションに追加することでnewHashメソッドで処理できるようになります。
Java SE 1.6
J2SE 1.5のnewHashのみになったみたいです。
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}Java SE 1.7
hashSeedというハッシュの初期化値が0以外かつキー値がString型の場合は別処理にてハッシュ値を求めるようです。(デフォルト:0)
上記以外はJava SE 1.6と同じかと思いきやキー値のハッシュ値と0でXOR演算しているため若干処理が変わってるようです。
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}Java SE 1.8
処理の見直しがされたようで今までのとはかなり変わっています。
内容的にはハッシュコードが衝突した場合のパフォーマンス改善を行っているようです。
使ってあれこれキー値の検索をしているようです。
public V put(K arg0, V arg1) {
return this.putVal(hash(arg0), arg0, arg1, false, true);
}
final V putVal(int arg0, K arg1, V arg2, boolean arg3, boolean arg4) {
HashMap.Node[] arg5 = this.table;
int arg7;
if(this.table == null || (arg7 = arg5.length) == 0) {
arg7 = (arg5 = this.resize()).length;
}
Object arg6;
int arg8;
if((arg6 = arg5[arg8 = arg7 - 1 & arg0]) == null) {
arg5[arg8] = this.newNode(arg0, arg1, arg2, (HashMap.Node)null);
} else {
Object arg9;
label79: {
Object arg10;
if(((HashMap.Node)arg6).hash == arg0) {
arg10 = ((HashMap.Node)arg6).key;
if(((HashMap.Node)arg6).key == arg1 || arg1 != null && arg1.equals(arg10)) {
arg9 = arg6;
break label79;
}
}
if(arg6 instanceof HashMap.TreeNode) {
arg9 = ((HashMap.TreeNode)arg6).putTreeVal(this, arg5, arg0, arg1, arg2);
} else {
int arg11 = 0;
while(true) {
arg9 = ((HashMap.Node)arg6).next;
if(((HashMap.Node)arg6).next == null) {
((HashMap.Node)arg6).next = this.newNode(arg0, arg1, arg2, (HashMap.Node)null);
if(arg11 >= 7) {
this.treeifyBin(arg5, arg0);
}
break;
}
if(((HashMap.Node)arg9).hash == arg0) {
arg10 = ((HashMap.Node)arg9).key;
if(((HashMap.Node)arg9).key == arg1 || arg1 != null && arg1.equals(arg10)) {
break;
}
}
arg6 = arg9;
++arg11;
}
}
}
if(arg9 != null) {
Object arg12 = ((HashMap.Node)arg9).value;
if(!arg3 || arg12 == null) {
((HashMap.Node)arg9).value = arg2;
}
this.afterNodeAccess((HashMap.Node)arg9);
return arg12;
}
}
++this.modCount;
if(++this.size > this.threshold) {
this.resize();
}
this.afterNodeInsertion(arg4);
return null;
}テスト
import java.util.HashMap;
import java.util.Iterator;
public class HashMapTest {
public static void main(String args[]){
HashMap testMap = new HashMap();
testMap.put("aaa", "111");
testMap.put("bbb", "222");
testMap.put("ccc", "333");
testMap.put("ddd", "444");
testMap.put("eee", "555");
testMap.put("fff", "666");
testMap.put("ggg", "777");
testMap.put("hhh", "888");
for(Iterator iterator = testMap.keySet().iterator(); iterator.hasNext();){
String key = (String) iterator.next();
String value = (String) testMap.get(key);
System.out.println(key+":"+value);
}
}
}1.4~1.8のバージョンを上記ソースで行っています。(1.4に合わせたソースになってます。)
実行結果(コンソール出力)とHashMap内の配列状況をまとめました。
結果
配列はEclipseのデバックモードにてtestMap.tableで取得した値です。
()内は同じIndex番号に入っている値です。
J2SE 1.5はnewは起動オプション(-XX:+UseNewHashFunction)を設定しています。
| 実行結果 | 配列 | |
|---|---|---|
| 1.4 | fff:666 ccc:333 aaa:111 ggg:777 eee:555 ddd:444 bbb:222 hhh:888 | [hhh=888, null, null, null, null, null, bbb=222, ddd=444, ggg=777(eee=555), null, null, aaa=111, ccc=333, null, fff=666, null] |
| 1.5 (old) | fff:666 ccc:333 aaa:111 ggg:777 eee:555 ddd:444 bbb:222 hhh:888 | [hhh=888, null, null, null, null, null, bbb=222, ddd=444, ggg=777(eee=555), null, null, aaa=111, ccc=333, null, fff=666, null] |
| 1.5 (new) | eee:555 bbb:222 ccc:333 ggg:777 ddd:444 aaa:111 fff:666 hhh:888 | [hhh=888, null, fff=666, aaa=111, ddd=444, null, null, null, null, ggg=777, ccc=333, null, null, null, bbb=222, eee=555] |
| 1.6 | hhh:888 fff:666 aaa:111 ddd:444 ggg:777 ccc:333 bbb:222 eee:555 | [hhh=888, null, fff=666, aaa=111, ddd=444, null, null, null, null, ggg=777, ccc=333, null, null, null, bbb=222, eee=555] |
| 1.7 | hhh:888 fff:666 aaa:111 ddd:444 ggg:777 ccc:333 bbb:222 eee:555 | [hhh=888, null, fff=666, aaa=111, ddd=444, null, null, null, null, ggg=777, ccc=333, null, null, null, bbb=222, eee=555] |
| 1.8 | aaa:111 ccc:333 bbb:222 eee:555 ddd:444 ggg:777 fff:666 hhh:888 | [aaa=111, null, ccc=333, bbb=222, eee=555, ddd=444, ggg=777, fff=666, null, hhh=888, null, null, null, null, null, null] |
各バージョン取得する順序はバラバラですね。Java SE1.6と1.7が同じ値だったのは意外でした。
また、J2SEとJavaSEで値を取得する順序も違うっていうのは面白いですね。
KeySetで確認しても同じでしたのでIteratorの違いというよりKeySetクラスの仕様が変わったのかな。
まとめ
HashMapは結構手を入れらてるんですね。各バージョンによって同じ値を入れた場合でも取得順は異なるということがわかりました。
JAVAのバージョンアップを行う際は注意したほうがよさそうですね。
(順序保証されていないので順番に取得しようとしてるのはどうかと思いますが。)
{kind=link}